机器学习基础
本文是 Björn Schuller 教授的人工智能课程的第二部分。
机器学习
目标
在传统的算法编程中,我们通常是编写好规则,然后把数据输入到规则里面,最后获取到输出的答案。而在机器学习中,我们需要准备一系列的数据和相对应的正确答案,让机器根据它们来输出一个合适的规则,使得该规则能够最大程度地实现数据到正确答案的转换。
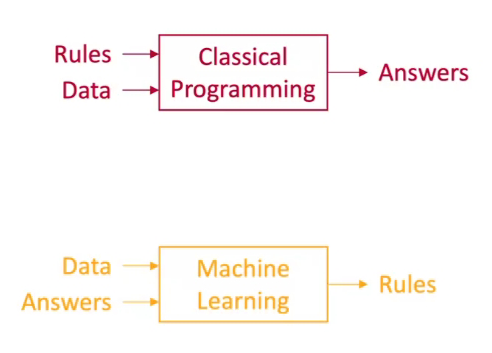
可以说,机器学习的目标是找到合适的规则来应用于数据,它是需要根据数据来训练的,而不是显式地编程的。不像常规的统计分析或者优选法,机器学习所学习到的规则,不能仅仅适用于所提供的训练数据,而是需要泛化(Generalization)到新的数据的,或者说是高度鲁棒的(Robust)。这就好比我们针对某一种现象进行了建模,因此规则也被称为模型(Model)。
用数学的术语说,我们需要找到一个从特征空间 $X$ 到标签空间 $Y$ 的映射函数 $f$。当我们给这个函数提供一个从未出现的、无标签的特征 $X_*$ 时,函数会将其映射到预测的标签 $Y_*$。
机器学习算法是创建模型的算法,它需要关注如何从大量的数据中进行模式识别。这一过程通常是迭代的过程——在学习阶段优化模型的参数,以提高模型性能。而深度学习是一种特殊形式的机器学习算法。
完成机器学习需要哪些资料呢?
- 大量的数据点。
- 这些数据点对应的正确答案,也就是预期输出,或者叫标签(Label)。
- 能够对训练出的模型给出优劣评价的算法。它用于衡量预测值和真实值的“距离”,并据此对现有模型进行调整。
数据点中包含了大量的特征。特征(Feature)是数据的表示,并且每个特征都是一个可以被机器用于决策的、独立的信息点。通常,不同种类的特征可以被集中在一起,形成特征向量(Feature Vector)。机器学习需要负责从特征向量中学习如何识别出特定的模式(Pattern)。
非深度学习架构下,特征在被给到机器学习算法之前,大多需要进行特征的预提取。寻常的机器学习处理流程如下图所示:
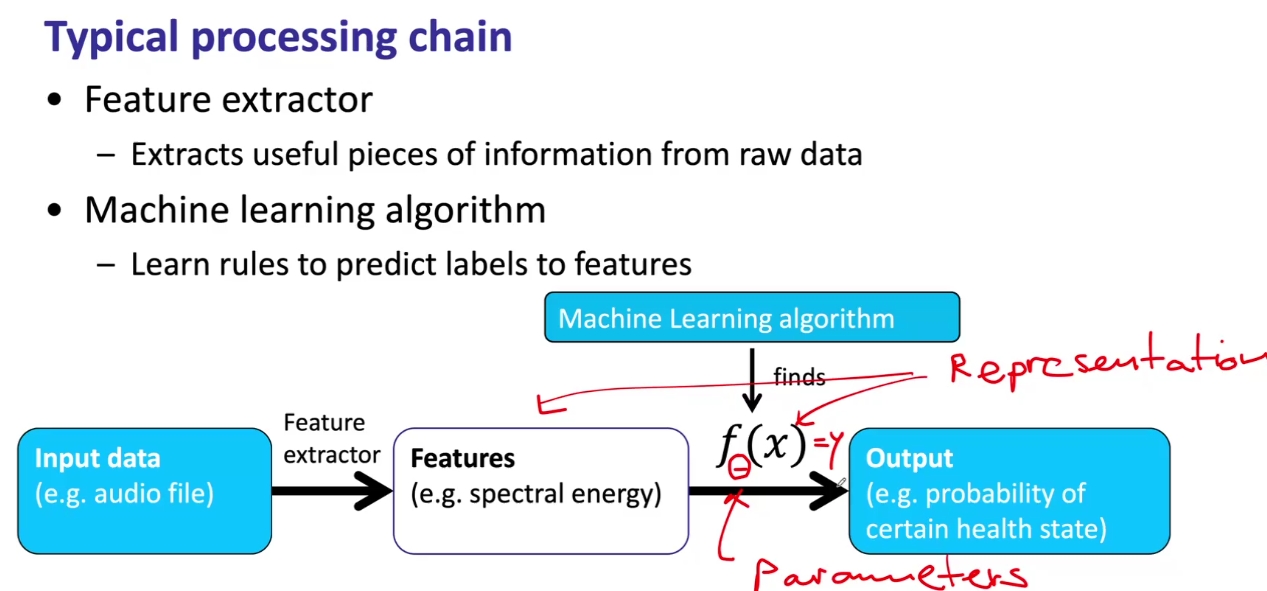
阶段
机器学习主要分为两个阶段。
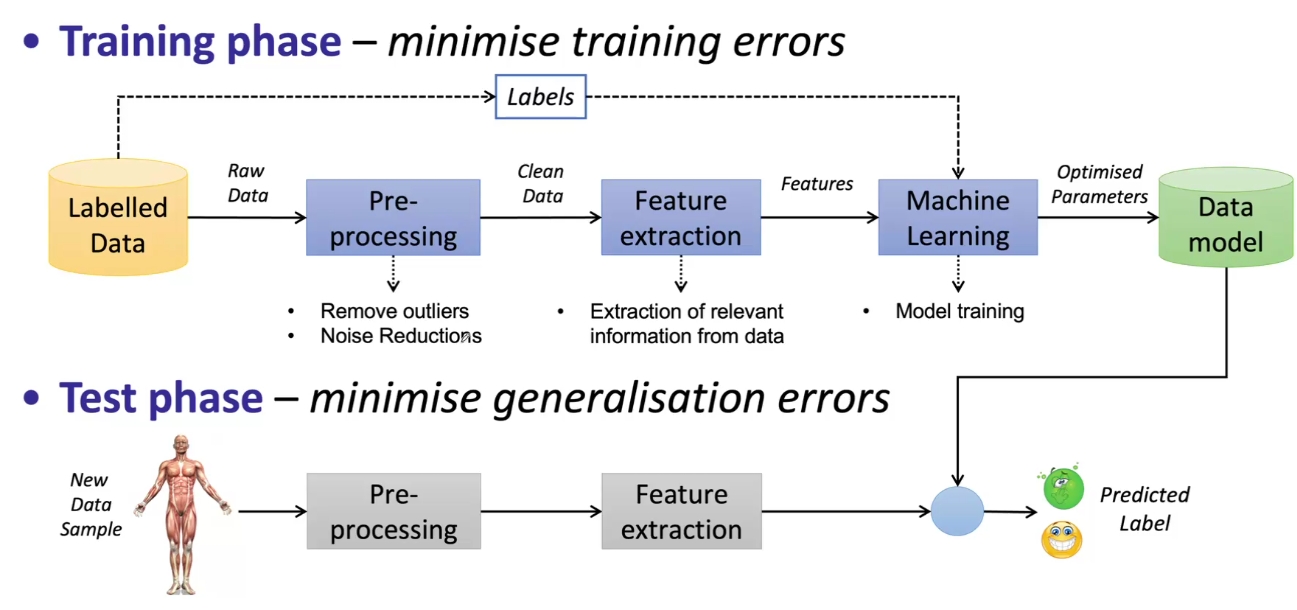
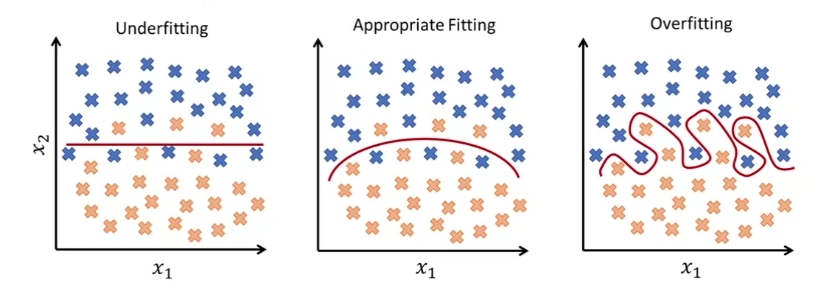
往往在测试阶段我们会发现一些泛化误差,这主要包括:
- 欠拟合(Underfitting):模型过于简单了,它缺乏对某些数据的敏感性。
- 过拟合(Overfitting):模型过于复杂了,它尝试去记住训练数据中出现的所有细节特征。
常见算法
常见的机器学习算法包括:
- 支持向量机(Support Vector Machine)。
- 高斯混合模型(Gaussian Mixture Model)。
- 隐马尔可夫模型(Hidden Markov Model)。
- 决策树(Decision Tree)。
- K 均值聚类(K-means)。