计算机中的数据表示
本文是《数据与计算思维》课程的一部分。
数据与计算思维
数据,是传达信息的集合。 例如数值、文字、图像、音频等都是数据,能给我们传递具体的信息。
In common usage, data is a collection of discrete or continuous values that convey information, describing the quantity, quality, fact, statistics, other basic units of meaning, or simply sequences of symbols that may be further interpreted formally.
计算思维,是指通过计算机可以做到的方式,来分析、表达和求解问题,并设计自动化的解决方案的思维能力。 计算机不是人,计算机必须依据精确完美的程序才能执行任务。简单地说,计算思维能让我们知道怎么写程序能让计算机解决问题。
Computational thinking (CT) refers to the thought processes involved in formulating problems so their solutions can be represented as computational steps and algorithms. In education, CT is a set of problem-solving methods that involve expressing problems and their solutions in ways that a computer could also execute. It involves automation of processes, but also using computing to explore, analyze, and understand processes (natural and artificial).
离散数据的表示
所谓离散数据(discrete data),是相对于连续数据(continuous data)而言的。通俗地说,离散数据就比如一个数字或一些文字,数据内包含的具体细节(数字或文字的个数)是可被计数的。连续数据就比如图像——在现实世界中,谁能说清人眼看到的一个画面是由多少像素点组成的呢?
我们先来了解一下离散数据在计算机中是如何被表示的。
二进制
首先需要了解一个事实,计算机内存储数据的方式是采用二进制(binary)。之所以采用二进制,是因为物理上实现起来简单——利用电路的开合就可以实现了。
零和一
类比十进制(decimal)的“逢10进1”,二进制的规则是“逢2进1”,二进制中唯一出现的数字是 0 和 1。举例:
0D=0B 1D=1B 2D=10B 3D=11B 4D=100B
0 也可理解为假(否)和断开(低电平、无信号)。1 也可理解为真(是)和连通(高电平、有信号)。
位和字节
存储1位二进制数所需的空间称为位(bit, b),也叫比特。存储8位二进制数所需的空间为字节(Byte, B)。有换算关系:
$ 1B(Byte)=8b(bit) $
位是最小的存储单位,字节是最小的可寻址单位。
更大的存储单位之间是以 $ 2^{10}=1024 $(而非 $ 1000 $)为一个级别来换算的。有换算关系:
$ 1KB=1024B \ $
$ 1MB=1024KB \ $
$ 1GB=1024MB \ $
除此之外,依次还有 TB,PB,EB,ZB 等单位。
进制转换
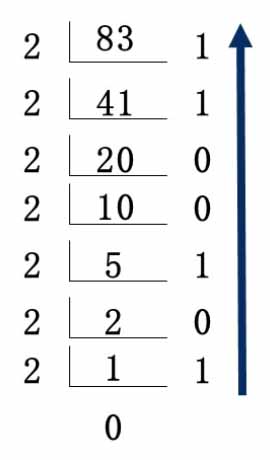
十进制到二进制的换算,整数部分可采用除二取余法(短除法的一种):用整数部分不断除以2,并记下每次的余数,直到商为0为止。所得余数从下至上读取即为转换结果。下图演示了 $ 83D=1010011B $:
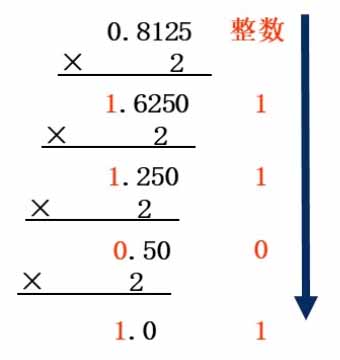
十进制到二进制的换算,小数部分可采用乘二取整法:用小数部分不断乘以2,并记下积的整数部分,直到积的小数部分为0,或精度达到要求为止。所得整数从上至下即为转换结果。下图演示了 $ 0.8125D=0.1101B $:
而二进制换算回十进制就比较简单了,直接按位权累加即可。

如你所见,大部分十进制小数是不能被二进制小数精确地表示的,只有完全契合二进制位权模式的数才能被精确表示。
数值数据
无符号整数
没有正负号的无符号整数(unsigned integer) 直接用二进制就能表示了。
$ n $ 位无符号整数的表示范围是 $ [0, 2^n) $。
有符号整数
有正负号的有符号整数(signed integer) 的表示就稍微复杂一点了。
假设有符号整数使用8位存储,最朴素的实现方法就是将该字节的最高位(最左侧位)变成符号位,0 表示正号、1 表示负号。这种表示方法称为原码(sign magnitude),举例:
3D=00000011B,-3D=10000011B
但是,这样的存储方式,会导致异号数值相加(同号数值相减)变得繁琐。如何设计一种表示方法,能够通过二进制码的直接相加,来实现异号数值相加(同号数值相减)?
考虑一个只有时针的钟表,它能够存储的无符号整数的范围是 $ [0, 12) $。假如我要把时针往回拨7小时($ -7 $),就等价于往前拨5小时($ +5 $),这是因为 $ 12 - 7 = 5 $,此时的 $ 5 $ 就称为 $ -7 $ 对于 $ 12 $ 的补数。
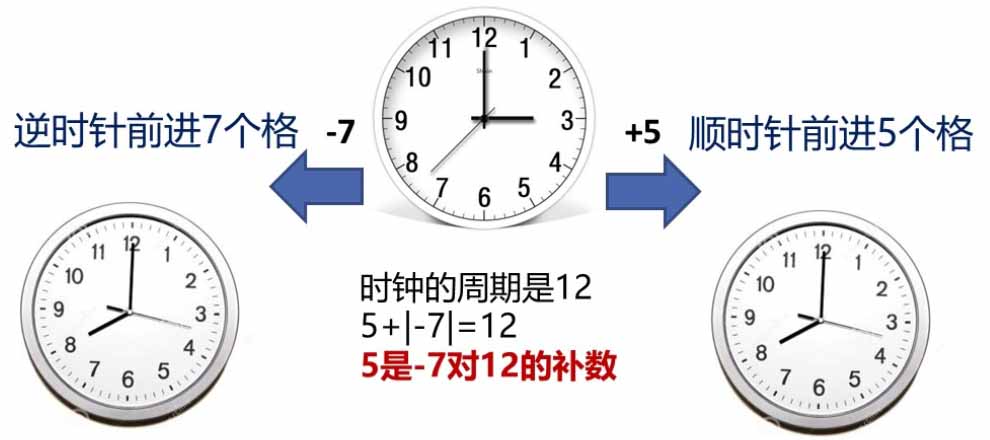
同样的,要想二进制码也实现“以加代减”,我们只需要找到负数的补码(complement) 即可。考虑一个8位有符号二进制数,它能够存储的无符号整数的范围是 $ [00000000B, 01111111B) $。类比钟表,易证,负数 $ -n $ 的补码的表达式是 $ 01111111B - n $。可以证明,负数 $ -n $ 的补码是将 $ |-n| $ 的原码按位取反后再 $ +1 $,而正数的补码就是其原码。
下面检验用补码表示的 $ 3+(-3) $ 的结果是否正确:
因为 $ 3D=00000011B $ 且 $ -3D=10000000B+(\sim0000011B)+1B=11111101B \ $
所以 $ 3D+(-3D)=00000011B+11111101B=100000000B $我们发现,结果的后8位变成了全0,此时舍去第1位,便有
00000000B=0D。
由于符号位的存在,$ n $ 位有符号整数的表示范围是 $ [-2^{n-1}, 2^{n-1}) $。通常,当我们提及整数(integer) 一词的时候,我们默认指的是有符号整数。
浮点数
如果我们想要表示小数呢?早期的计算机采用的是“定点数”的方法,所谓“定点”就是“小数点的位置是固定的”。比如我们可以约定,在8位中,前4位表示小数点前的数,后4位表示小数点后的数。但是这样的表示方法很显然效率比较低下,于是就出现了“浮点数”。
所谓“浮点”,就是我的小数点是可以“移动”的,不是固定在某个位上的。32位的早期浮点数是这样规定的:

早期浮点数表示法:
- 标准化: 对于任意二进制小数,将其标准化为 $ \pm 0.N \times 2^K $ 后,设 $ N $ 为尾数,$ K $ 为指数。
- 前8位:指数(exponent),是有符号的补码,范围是 $ [-128, 128) $。
- 后24位:尾数(fraction),是有符号的原码。
尾数部分不采用补码的原因是,补码对增加浮点运算的速度没有太大帮助。
需要注意的是,目前(21世纪早期)采用的浮点数大多是 IEEE 754 规范,与上面所述的早期表示方法略有区别。32位的 IEEE 754 浮点数是这样规定的:

IEEE 754 表示法:
- 标准化: 对于任意二进制小数,将其标准化为 $ \pm 1.N \times 2^K $ 后,设 $ N $ 为尾数,$ K $ 为指数。
- 第1位:符号位,控制整个数的符号。
- 接着8位:指数,但不同之处是,这里的指数是无符号的移码,不能直接使用,范围是 $ [0, 256) $。要想把它转化到 $ [-128, 128) $ 范围,直接 $ -128 $ 就行了。
- 后23位:尾数,是无符号的原码。
IEEE 754 约定标准化后的整数部分都是1,一定程度上扩展了能表示的有效位数。
32位的浮点数被称为单精度浮点数(single float),有1符号位+8指数位+23尾数位;64位的浮点数被称为双精度浮点数(double float),有1符号位+11指数位+52尾数位。
我们来简单讨论一下浮点数的精度。单精度浮点数有23位二进制尾数,由于 $ lg2^{23} \approx 6.92 $,因此单精度浮点数可以表示6到7位有效数字。双精度浮点数有52位二进制尾数,由于 $ lg2^{52} \approx 15.65 $,因此双精度浮点数可以表示15到16位有效数字。
文本数据
西文字符
为了存储文本数据,在计算机中,要为每个字符指定一个二进制代码(字符编码),作为识别与使用这些字符的依据。最基础的编码规则是美国标准信息交换码(American Standard Code for Information Interchange, ASCII)。
ASCII 编码规则:
- 用1个字节表示1个字符的编码。
- 第1位固定是0。
- 后7位用于编码:控制字符、阿拉伯数字、大小写英文字母和部分标点符号。
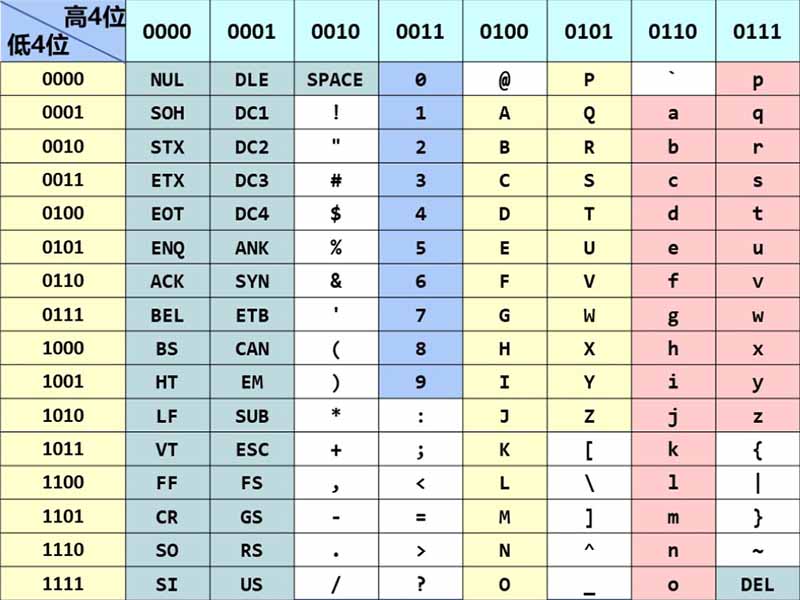
其中,需要记住的重要ASCII字符有:
| NUL | LF | CR | SPACE | 0 | A | a | |
|---|---|---|---|---|---|---|---|
| Bin | 00000000 |
00001010 |
00001101 |
00000010 |
00110000 |
01000001 |
01100001 |
| Dec | 0 |
10 |
13 |
32 |
48 |
65 |
97 |
| Hex | 00 |
0A |
0D |
20 |
30 |
41 |
61 |
提示:
上表的“Hex”指的是十六进制(Hexadecimal)。十六进制采用
A,B,C,D,E,F来分别表示10,11,12,13,14,15。每4个二进制数可以转化为1个十六进制数。另外,不难发现,ASCII小写字母的编码是大写字母基础上的 $ +32D $ 或 $ +20H $。
那我其他欧美文字怎么办?正好ASCII的第1位是固定为0的,没有充分利用起来。我们把它变成1后,就又可以存储128个字符了。这样产生的编码规则被称为 ISO 8859 ,即扩展ASCII字符集,主要用于拉丁语系。
中文字符
汉字是记录汉语的表意文字,具有字符数量极多(数万个字符)、字形字音复杂等特点。
要想向计算机输入汉字,通常我们需要借助输入法(input method),这一过程是输入码的转换。区位码、五笔和拼音都是经典的汉字输入法。要想让计算机显示汉字出来,就需要将汉字转换为点阵图形,这一过程是输出码即字形码的转换。
上面简单介绍了输入和输出汉字的过程,那么计算机是如何存储和传输汉字的呢?中国制定的汉字编码规则是 GB 2312(1980年的国标码)及其扩展版本 GBK。
GB 2312 编码规则:
- 用2个字节表示1个字符的编码。
- 每个字节的第1位都固定是0。
- 每个字节预留出取值为 $ [0D, 32D] \cup 127D $ 的34个编码(为了与ASCII及其控制字符兼容)。
- 每个字节的有效取值为 $ [33D, 126D] $ 即 $ [21H, 7EH] $,可以独立表示 $ 94^2=8836 $ 个字符。
GB 2312 的编码概览如下图所示,行头表示高8位,列头表示低8位。其中,一级汉字区(常用汉字)里的汉字按照汉语拼音排序,二级汉字区里的汉字按照部首和笔画排序。
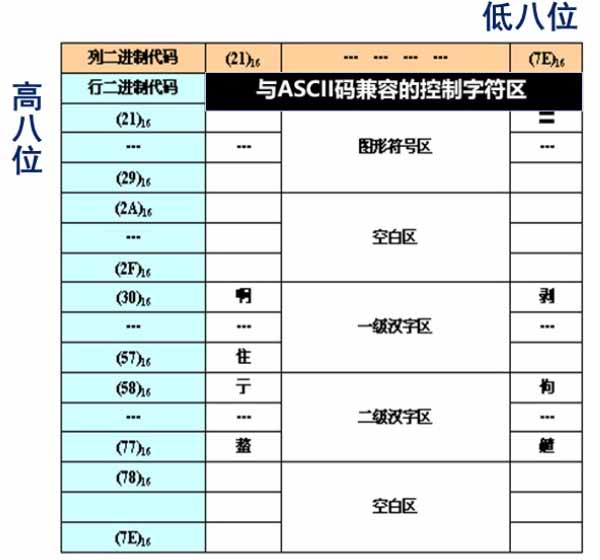
可惜,计算机中如果按照这样(每个字节的第1位为0)存储国标码的话,会与ASCII冲突。所以,国标码在计算机中需要相应地把每个字节的第1位调整为1来存储,这样的编码方式被称为汉字的机内码(machine code)。尽管这会与ISO 8859冲突,但至少不会和ASCII冲突了,早这样设计国标码不就行了?
接下来我们看看GB 2312的有效编码区域,如下图所示,高8位和低8位的有效区段共同围合成了一个边长为94的正方形区域。
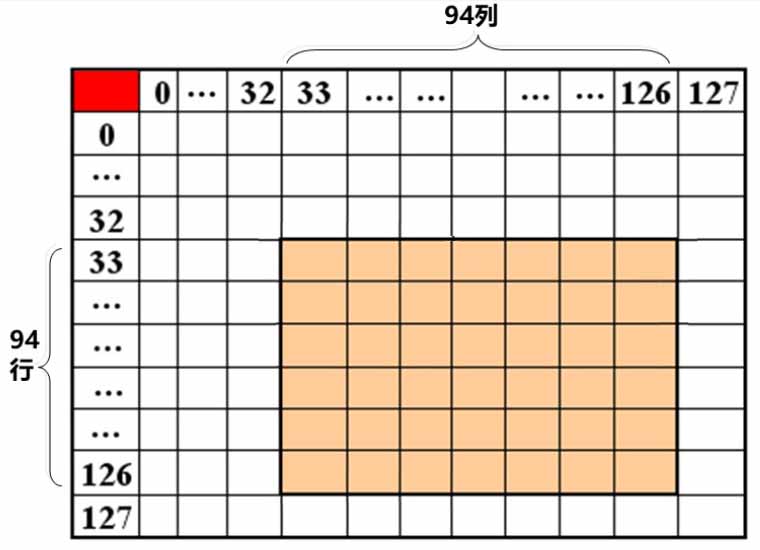
假设最左上的汉字的坐标为 $ y=1, x=1 $,最右下的汉字坐标为 $ y=94, x=94 $,则可将最左上的汉字记作 $ 0101D $,最右下的汉字记作 $ 9494D $。这样使用4个十进制数来编码汉字的方式被称作区位码(QW code),用于人类对汉字进行查找和分类。区位码的前2个数是区号,后2个数是位号。
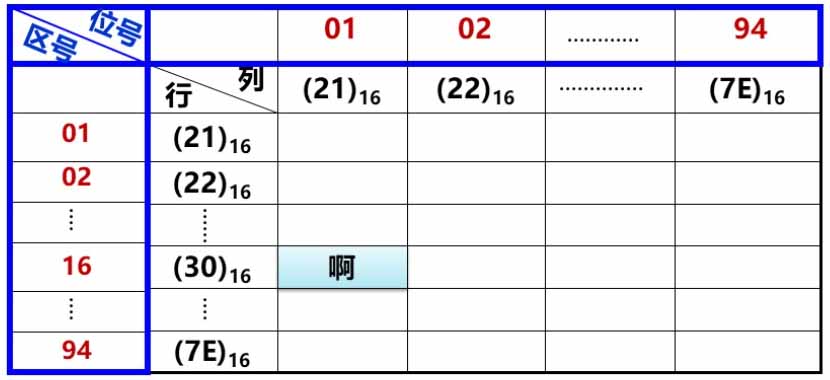
目前为止,围绕GB 2312产生了3种“码”:国标码、机内码和区位码。它们比较容易混淆,下面给出三者的对比:
- 国标码(GB 2312)是原生的编码标准,采用2字节二进制数或4位十六进制数来表示。
- 机内码是国标码在计算机中的实际存储形式,也是十六进制。国标码 $ +8080H $ 就可得到机内码。
- 区位码不是给计算机使用的,主要是给人类用来分类和查找汉字用的,采用4位十进制数来表示。国标码 $ -2020H $ 再转为十进制就可得到区位码。
世界字符
现代人类使用的语言达上千种,光是处理中文和西文肯定不行。在计算机文本处理中,应允许能同时使用任意多种语言的字符才行。我们迫切需要一种统一的、支持多语言的编码方案。于是, Unicode标准 应运而生。
Unicode为每个字符分配了唯一的编号,即码位(code point)。但是Unicode并没有规定如何实现存储和传输编码。常见的Unicode编码实现是UTF-8和UTF-16。其中,UTF的全称是Unicode Transformation Format。
UTF-8 编码规则:
以8位(1字节)为一个编码单位,采用可变长编码(字符的字长不是固定的):
| 字长 | 内容 | 起始值 | 终止值 | Byte1 | Byte2 | Byte3 | Byte4 |
|---|---|---|---|---|---|---|---|
| 1B | ASCII字符 | U+0000 |
U+007F |
0xxxxxxx |
|||
| 2B | 拉丁文和希腊字母等 | U+0080 |
U+07FF |
110xxxxx |
10xxxxxx |
||
| 3B | 中日韩字符等 | U+0800 |
U+FFFF |
1110xxxx |
10xxxxxx |
10xxxxxx |
|
| 4B | 扩展字符 | U+10000 |
U+10FFFF |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
UTF-16 编码规则:
以16位(2字节)为一个编码单位,采用定长编码。有大端(Big Endian, BE)和小端(Little Endian, LE)之分,大端是高8位在前,小端是低8位在前。
UTF-8适用于拉丁字符较多的场合,并且没有字节顺序问题,所以相比于UTF-16更加适合网络通信。
连续数据的表示
计算机只能处理有限而离散的二进制数据(数字数据),因此对于图像和音频等连续的数据(模拟数据),会将其先转化为离散数据。这一过程称为数字化(digitization),它必然会丢失现实世界中的一些细节。
图像数据
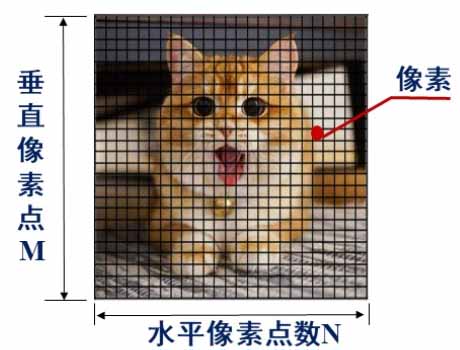
数字图像是具有一定 分辨率(resolution) 和一定的颜色数量或者说 位深度(bit depth) 的图像,组成图像的每个 像素(pixel, px) 均具有一个特定的颜色值,相邻像素的颜色值变化是离散的。
像素是计算机生成和渲染图像的基本单位。分辨率是描述图像的像素规模的指标。
现实世界中的模拟图像在二维坐标上的颜色值变化是连续的,即像素无穷多,颜色值无穷多。图像的数字化过程就是模拟图像转化为数字图像的过程。
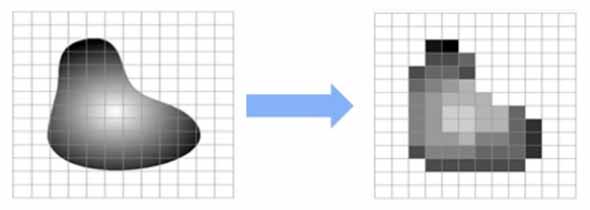
图像的数字化分为3个步骤——采样、量化和编码。
采样与量化
图像的 采样(sampling) 是对连续图像在二维空间上进行离散化处理,将二维空间上的连续色彩信息转化为一系列有限的离散数值。通俗地讲,这相当于给原始图像套上一个矩形网格,然后将每个网格里的平均颜色当作该网格的代表颜色,最终得到的矩形网格就只包含了有限的颜色信息。
图像的 量化(quantization) 是对像素的颜色表示进行离散化,也就是给每个像素的颜色都赋予一个具体的数值。
量化位数,即位深度描述了每个像素的颜色是以多少位二进制数存储在计算机中的。下方的3张图片,从左到右依次是1bit的黑白图(二值图)、8bit的灰度图(256个灰度等级)和24bit的彩色图(红绿蓝三种颜色的分量各由8bit表示)。

颜色系统
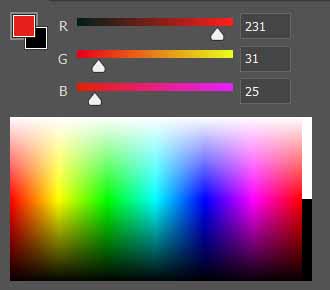
24bit的彩色图,可以表示 $ 256^3 = 16777216 $ 种颜色,自然界的色彩虽不能用数字归纳,但1.6千万种颜色已达人眼的分辨极限,能够基本反映原图的色彩,故又称真彩色图像。其颜色由红绿蓝(RGB)三种颜色混合而成,每种颜色的分量由8bit表示。像这样的颜色系统是RGB颜色系统。
24bit真彩色图像的颜色模式为
RGB888。有时,图像具有不透明度(opacity),它可以使用8bit的alpha值表示。带不透明度的32bit真彩色图像的颜色模式为RGBA8888。
将单独的一种颜色分离出来而形成的图片称为通道图,通道图通常是8bit灰度图。如下图所示,通道图中较亮的部分表示该区域的对应颜色分量较高。

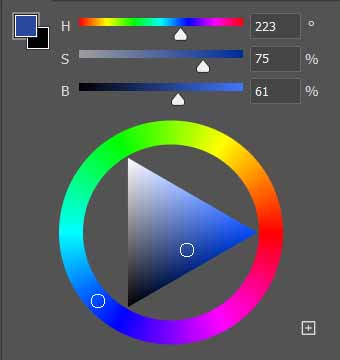
HSV颜色系统 也是常用的颜色系统,使用色相(Hue, H)、饱和度(Saturation, S)和亮度(Value, V)三个指标来表示一个颜色。这样的设定比较贴合人眼的视觉感知。色相是颜色在圆形色相环中所处的角度(0°为红色),饱和度指示颜色的鲜艳程度。亮度也译作brightness,因此该颜色系统又名HSB。
HSL颜色系统 也是常用的颜色系统,它类似于HSV颜色系统,L指的是light,即白光的分量。但它除了色相的概念和HSV一致,其他指标的计算都和HSV略有不同。下图展示了HSL与HSV的直观对比。

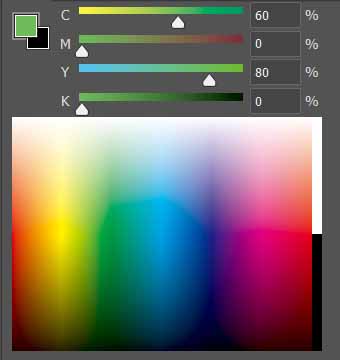
CMYK颜色系统 也是常用的颜色系统,使用青色(Cyan, C)、品红(Magenta, M)、黄(Yellow, Y)和黑色(blacK, K)四个指标来表示一个颜色。CMYK是基于物理上的光吸收-反射原理制定的,不难发现,青色=白色-红色,品红=白色-绿色,黄色=白色-蓝色。
除了上面提到的颜色系统外,还有很多颜色系统被应用于不同的场景中。例如YUV颜色系统使用一个亮度信号Y以及两个色差信号U和V的颜色定义,主要应用于电视行业中。黑白电视机只接收亮度信号Y,彩色电视机需要同时接收亮度信号Y以及色差信号U和V。
编码
在对图像进行采样和量化后,需要通过一定的编码手段将其存储起来。常见的编码的格式如下:
| 简称 | 全称 | 压缩 | 颜色模式 | 额外功能 |
|---|---|---|---|---|
| BMP | BitMaP | 不压缩 | RGB(A) | |
| PNG | Portable Network Graphics | 无损压缩 | RGB(A) | |
| GIF | Graphics Interchange Format | 无损压缩 | 256 Colors | 可存储动态图像 |
| JPEG | Joint Photographic Experts Group | 有损压缩 | Y’CbCr | |
| TIFF | Tagged Image File Format | 有损或无损压缩 | RGB/CMYK | 可存储额外标记 |
数据压缩
媒体数据具有数据量大和传输速率快的特点,在存储和网络传输时需要较大的存储空间和带宽。数据压缩技术旨在减少或消除原始数据中的冗余数据,使数据所占用的存储空间减少。
数据压缩包括 压缩(compressing)和解压缩(decompressing) 两个部分。解压缩就是从压缩数据恢复到原始数据的过程。如果某种压缩方法,它解压缩的数据总能与原始数据保持一致,那么这种压缩方法是无损压缩,反之是有损压缩。
压缩比的计算方法是 原始数据大小:压缩数据大小。压缩比越高则指示某种压缩方法的压缩效果越好。
下面介绍最简单的游程长度编码。
游程长度编码(Run Length Encoding, RLE) 是基于空间冗余思想的无损压缩方法。它采用“相同值的数量+相同的值”的方式来记录数据,例如 AAAABBBCC 使用RLE压缩后可以变为 4A3B2C。“游程长度”指的正是具有相同值并且连续的值的数量。
在图像中,一般要求先行后列地扫描图像,然后采用RLE进行数据压缩。RLE对于有大面积色块的图像具有较高的压缩比。
计算机中的数据表示